本帖最后由 SunFuture 于 2025-11-10 21:54 编辑
这系列文章是我当初发在某公众号上的,搬来分享给大家。
编程语言中,R是我认为最适合数据处理的。
《R for Data Science》是由被誉为“让 R 语言涅槃重生的男人”——Hadley Wickham 主编的一本入门教材。全书以 tidyverse 包为核心,由浅入深地讲解了数据可视化、数据框处理、Quarto文档等多方面的知识,为读者构建起简洁优雅的 R 语言数据科学大框架。
本书在线阅读网址:https://r4ds.hadley.nz/
前言
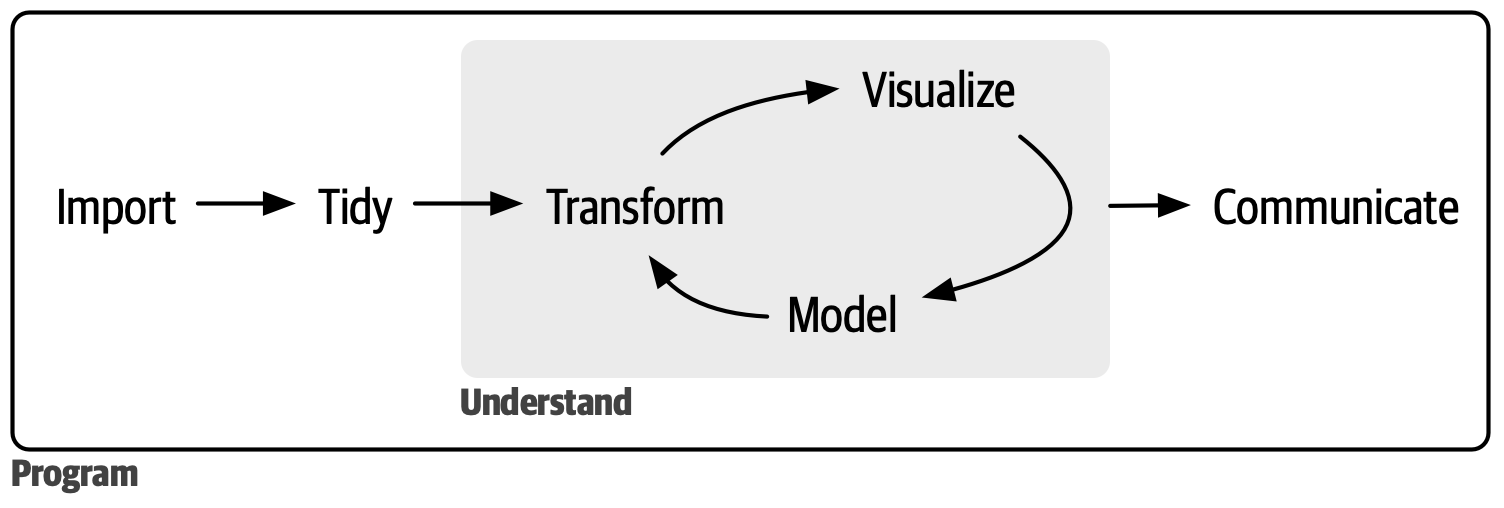
上图是完成一个数据科学项目的基本模型。
- 导入(文本文件、数据库、网页API)。显然,不将数据导入,就无法对其进行数据科学研究。
- 规整。目的是让数据结构尽量整洁,从而使分析者关注问题本身。
- 转换。包括缩小观测值范围、创建新变量、计算汇总数据等操作。
- 可视化。直观的图形能揭示数据中隐含的信息,同时也能验证某些猜想。
- 建模。是可视化的补充,若要进一步精确回答问题,就需要用模型解决。
- 交流。无论图画得多漂亮,模型建得多棒,最重要的是与其他人交流数据信息,集思广益。
上面的六个步骤都离不开编程。虽然数据科学研究者不需要登峰造极的编程技巧,但是学习一些基础的编程知识能够更方便地完成一些简单任务。
1. 数据可视化
1.1 引言
ggplot2是所有R可视化工具中最优雅的之一。
本章需载入下列R包:
library(tidyverse)
library(palmerpenguins) # 包含示例数据
library(ggthemes) # 提供色盲调色板
1.2 绘制企鹅数据图
本书开篇甩出一系列问题:企鹅的脚蹼长度和体重之间的关系是怎样的?是线性?非线性?这种关系是否因企鹅的种类而异?与地理位置有关吗?针对这些问题,我们将进行可视化操作以回答。
首先了解一些术语:
- 变量(variable)是可以测量的数量、质量等属性。
- 值(value)是测量变量时变量的状态。变量的值可能会因测量而异。
- 观测值(observation)是在相近条件下进行的一组测量 (通常就是在同一时间对同一对象的所有值)。一个观测值将包含多个值,每个值都与不同的变量相关联。
- 表格数据(tabular data)是一组值,每个值都与一个变量和一个观测值相关联。
接下来输入palmerpenguins::penguins以打开示例数据的数据框。注意到并未显示出所有变量。
> palmerpenguins::penguins
# A tibble: 344 × 8
species island bill_length_mm bill_depth_mm
<fct> <fct> <dbl> <dbl>
1 Adelie Torger… 39.1 18.7
2 Adelie Torger… 39.5 17.4
3 Adelie Torger… 40.3 18
4 Adelie Torger… NA NA
5 Adelie Torger… 36.7 19.3
6 Adelie Torger… 39.3 20.6
7 Adelie Torger… 38.9 17.8
8 Adelie Torger… 39.2 19.6
9 Adelie Torger… 34.1 18.1
10 Adelie Torger… 42 20.2
# ℹ 334 more rows
# ℹ 4 more variables: flipper_length_mm <int>,
# body_mass_g <int>, sex <fct>, year <int>
# ℹ Use `print(n = ...)` to see more rows
也可使用glimpse(penguins),查看所有变量和每个变量的前几个观测值的替代视图。
> glimpse(penguins)
Rows: 344
Columns: 8
$ species <fct> Adelie, Adelie, Adelie, Adelie, Ad…
$ island <fct> Torgersen, Torgersen, Torgersen, T…
$ bill_length_mm <dbl> 39.1, 39.5, 40.3, NA, 36.7, 39.3, …
$ bill_depth_mm <dbl> 18.7, 17.4, 18.0, NA, 19.3, 20.6, …
$ flipper_length_mm <int> 181, 186, 195, NA, 193, 190, 181, …
$ body_mass_g <int> 3750, 3800, 3250, NA, 3450, 3650, …
$ sex <fct> male, female, female, NA, female, …
$ year <int> 2007, 2007, 2007, 2007, 2007, 2007…
此外还可运行view(penguins),打开交互式数据查看器。
我们的目标是用可视化图显示这些企鹅的脚蹼长度和体重、种类之间的关系。所以接下来开始介绍ggplot()这一核心函数。
第一个参数是data,表示我们绘图所需的数据集,此处即ggplot(data = penguins)。但由于我们还没有声明具体绘图方式,因此现在画布尚为空白。
第二个参数为mapping,通常与美学函数(aes)成对出现。aes()函数中x和y的参数要分别映射到 x 轴和 y 轴,在本例中,我们将脚蹼长度映射到x,将体重映射到y,ggplot2 会在参数中查找映射的变量。故而输入:
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
)
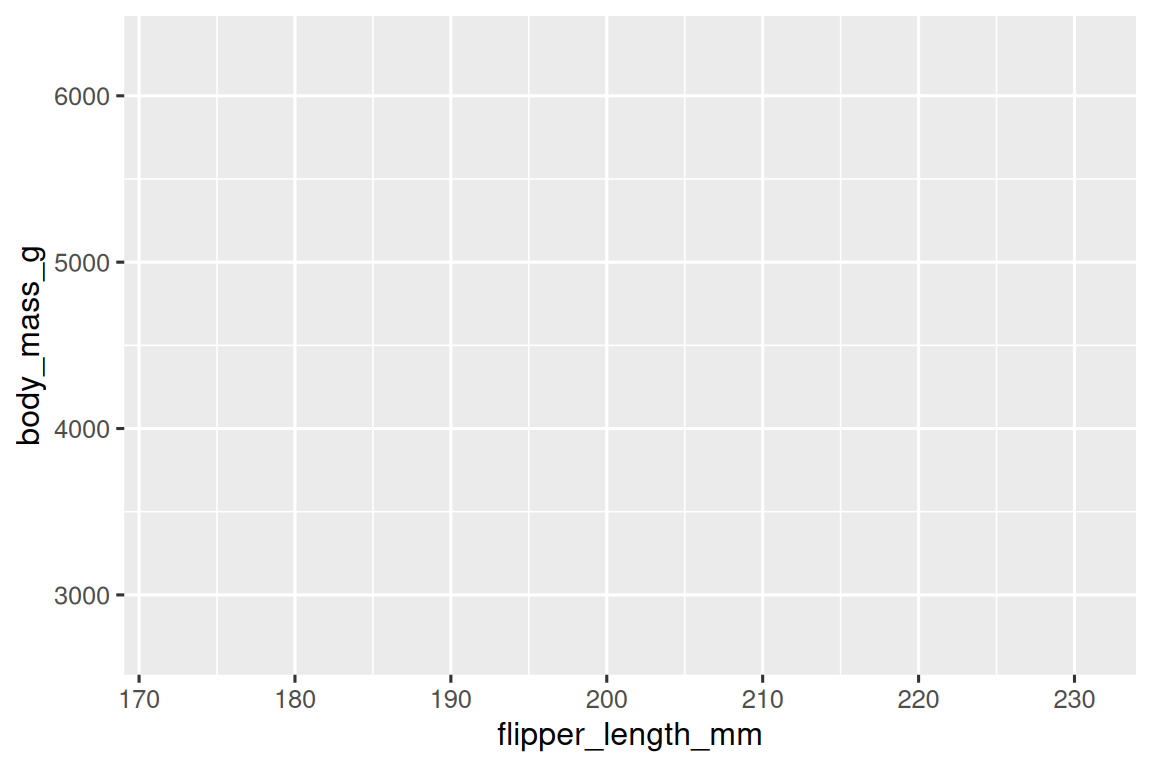
现在画布上出现了坐标轴,脚蹼长度为 x 轴,体重为 y 轴。但是还没有图线,因为尚未设置绘图模板。
下面定义绘图模板geom (geometric object)。不同类型的图以不同类型的基础几何图形组成。
- 条形图使用条形
geom_bar()
- 折线图使用线
geom_line()
- 箱线图使用箱型
geom_boxplot()
- 散点图使用点
geom_point()
注意geom函数与ggplot函数是并列的,二者以加号相连。不妨尝试画一个散点图:
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point()
#> Warning: Removed 2 rows containing missing values or values outside the scale range
#> (`geom_point()`).
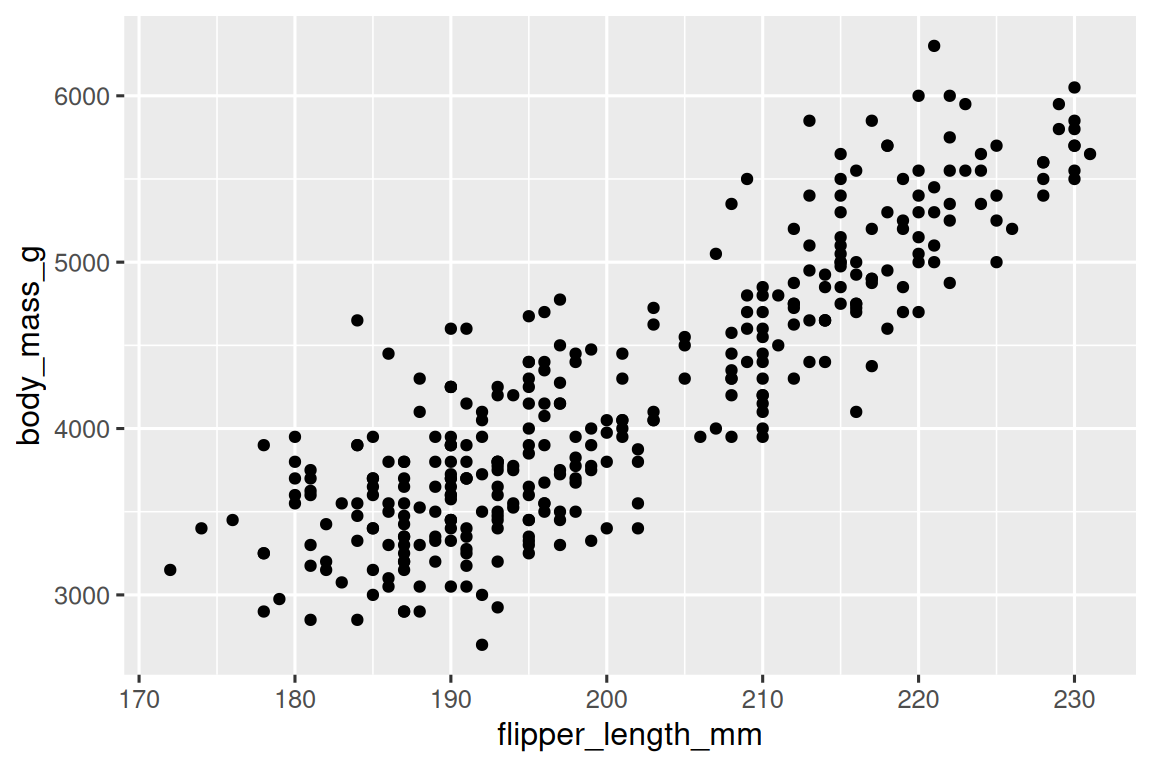
我们注意到生成图像时有警告信息,是因为数据中有两只企鹅缺少体重或脚蹼长度值,ggplot2 无法在图上表示缺失值。ggplot2 贯彻不让任何缺失值静默地缺失这一理念。
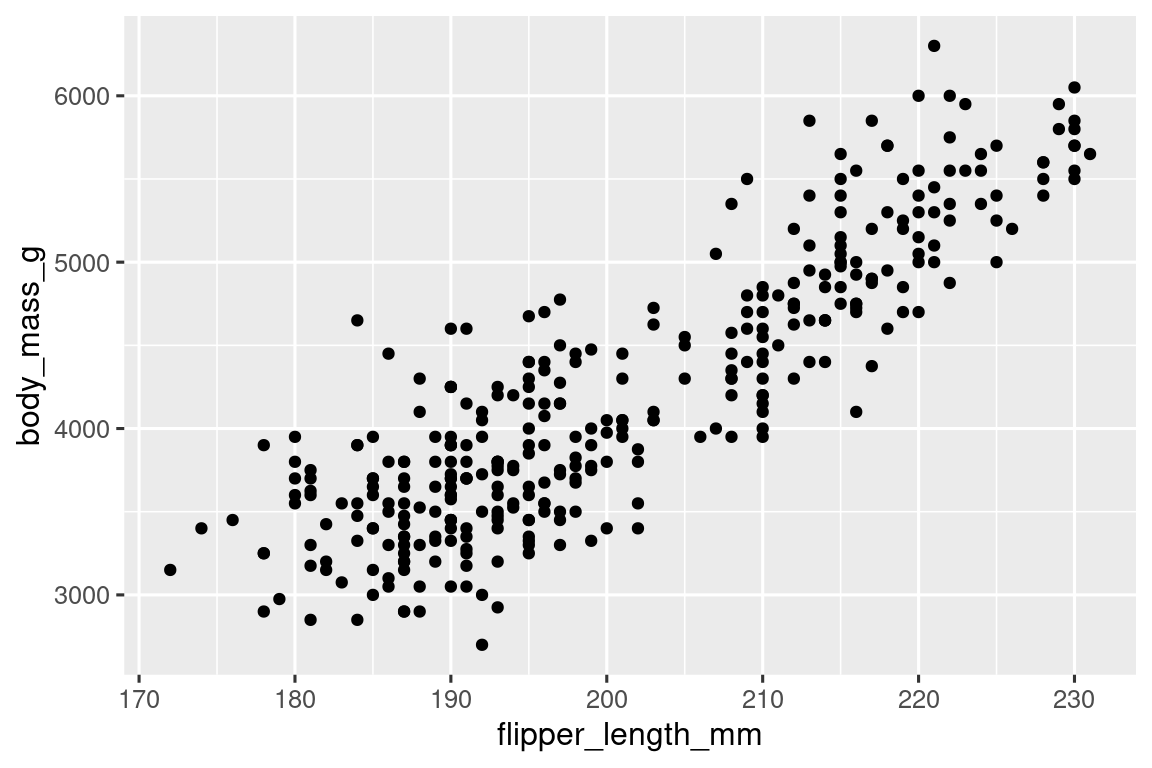
接下来,我们需要将物种这一变量纳入图中,可以通过使用不同颜色的点来表示不同物种。使用color=<变量>参数即可实现。绘制完成后可以发现ggplot2帮我们附上了一个图例。
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g, color = species)
) +
geom_point()
为了让图像更直观,最好再添加一个图层,以显示体重和脚蹼长度之间关系的平滑曲线,用geom_smooth()函数表示。由于平滑曲线是一个新的几何对象,与散点图并存,故而函数geom_smooth(method = "lm")也应独立,用加号连接。其中lm表示线性模型(linear model)。
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g, color = species)
) +
geom_point() +
geom_smooth(method = "lm")
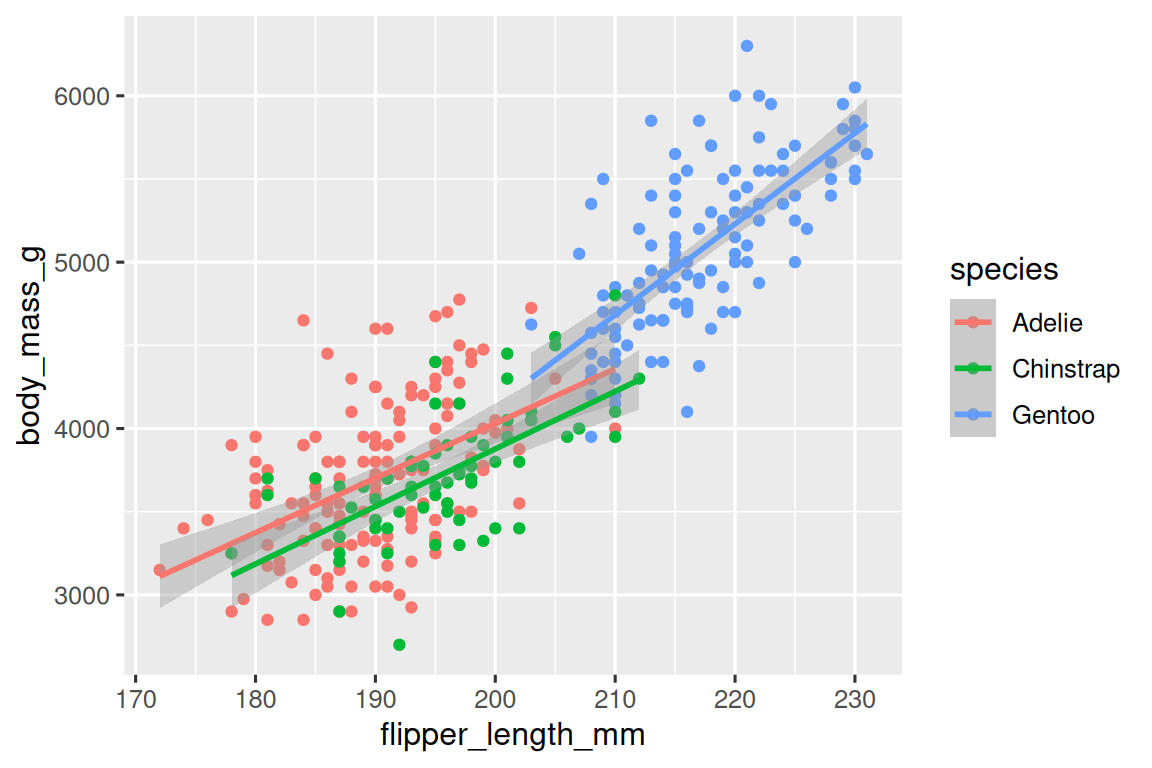
此代码输出的图包含三条线,分别表示三个物种,看起来颇为凌乱。如果曲线的对象是整个数据,就能做到只输出一条总线,那么如何设置?
实际上,ggplot函数里的参数是影响所有geom的,而各个geom函数里的参数则各自为营而互不干扰。因此可让颜色只在散点图中作为物种区分,从而不影响平滑曲线:
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point(mapping = aes(color = species)) +
geom_smooth(method = "lm")
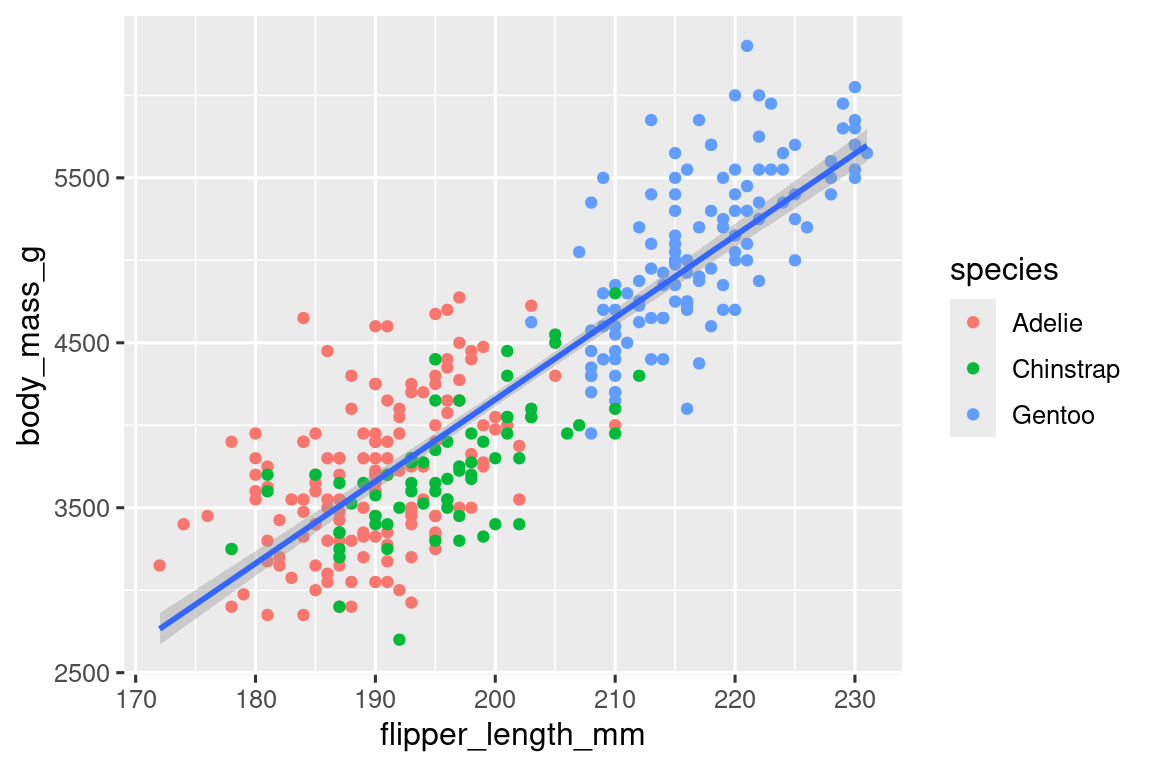
现在得到的图像美观多了,但仍有进步空间。考虑到色盲人士,只用颜色区分物种貌似不太妥当,可以将点改为多种形状来区分。使用shape=<变量>参数即可实现。同样也会附上图例。
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point(mapping = aes(color = species, shape = species)) +
geom_smooth(method = "lm")
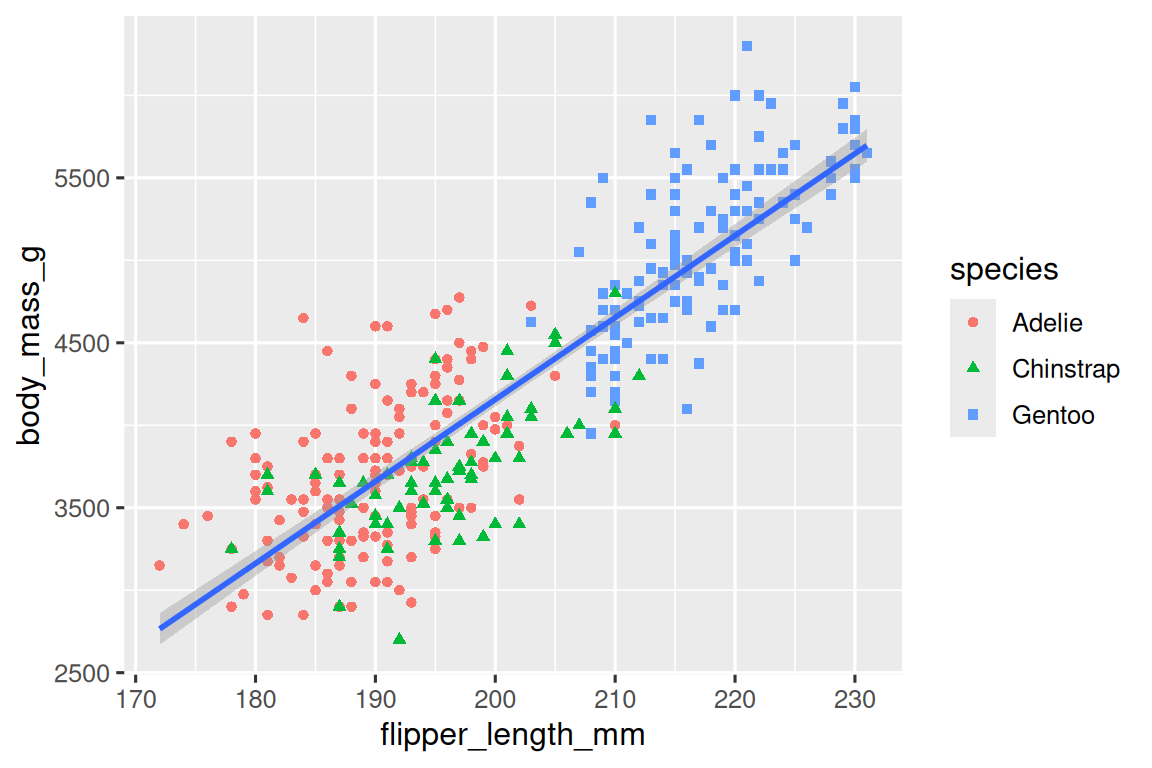
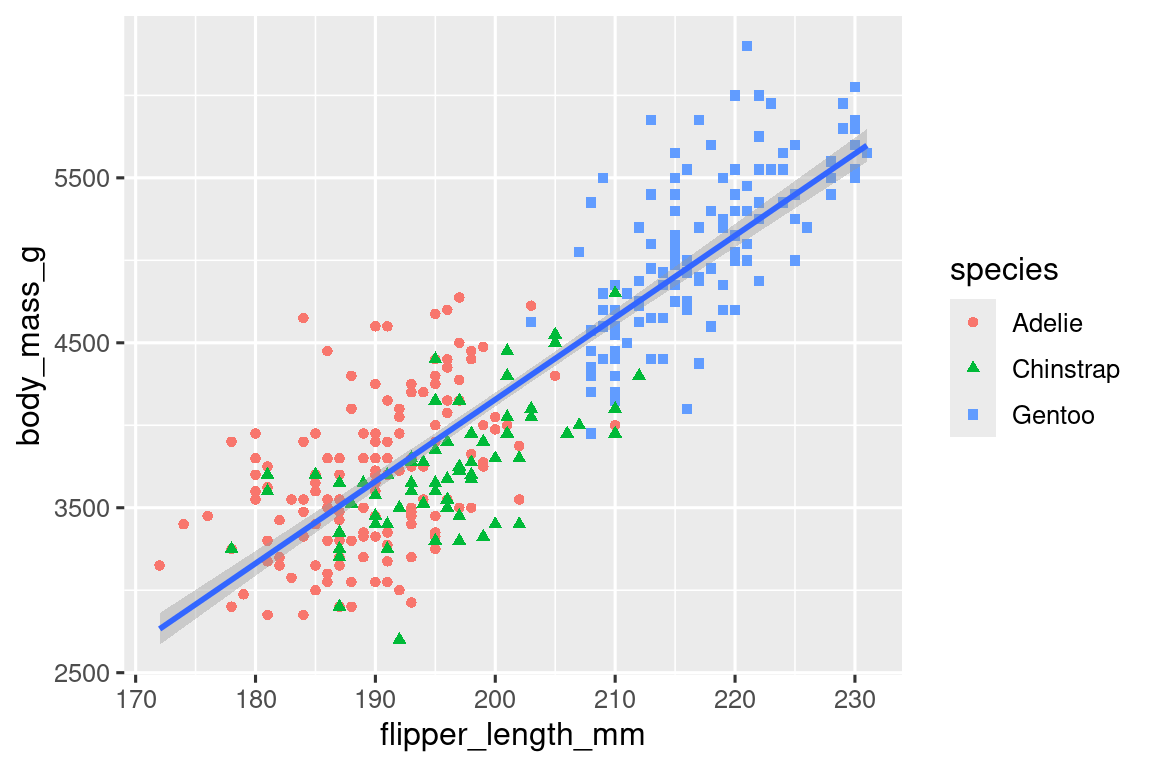
最后一步,我们可以添加一个用于解释图像的函数labs(),从而为图添加标题和副标题,并以与美学映射匹配的方式添加坐标轴文字,并定义图例的标签等等。此外,还可以使用 ggthemes 包中的函数改进调色板,进一步照顾色盲人士。
> ggplot(
+ data = penguins,
+ mapping = aes(x = flipper_length_mm, y = body_mass_g)
+ ) +
+ geom_point(aes(color = species, shape = species)) +
+ geom_smooth(method = "lm") +
+ labs(
+ title = "Body mass and flipper length",
+ subtitle = "Dimensions for Adelie, Chinstrap, and Gentoo Penguins",
+ x = "Flipper length (mm)", y = "Body mass (g)",
+ color = "Species", shape = "Species"
+ ) +
+ scale_color_colorblind()
1.3 调用 ggplot2
ggplot函数的核心用法已阐述完毕,下面将以更简洁的形式呈现,省略参数名称(data和mapping)。所以上一节中的某一命令可简化为:
ggplot(
data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point()
当然也可以借助R的管道进行简化:
penguins |>
ggplot(aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point()
1.4 分布可视化
如果要将企鹅的种类等**类别变量(categorical variable)**可视化,可使用条形图geom_bar()如下:
ggplot(penguins, aes(x = species)) +
geom_bar()
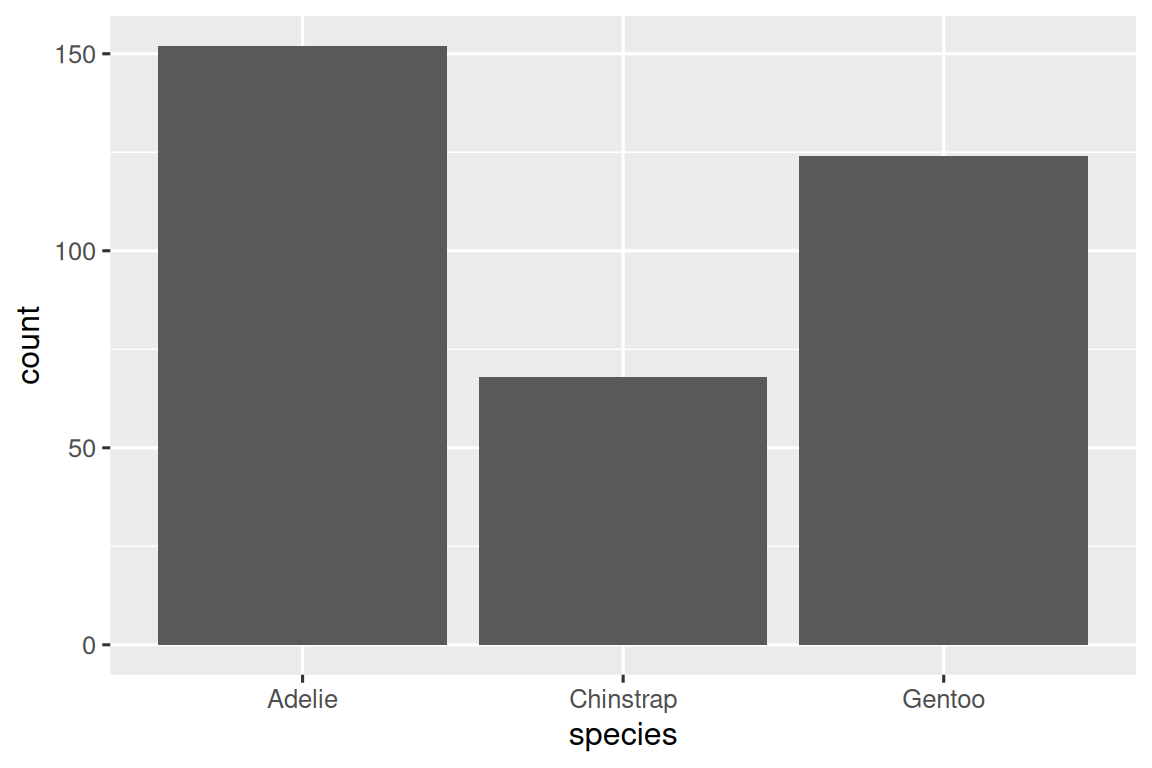
如此便可生成对应条形图,但是排列是无序的。借助fct_infreq()函数按照每个类别的数量进行降序排序:
ggplot(penguins, aes(x = fct_infreq(species))) +
geom_bar()
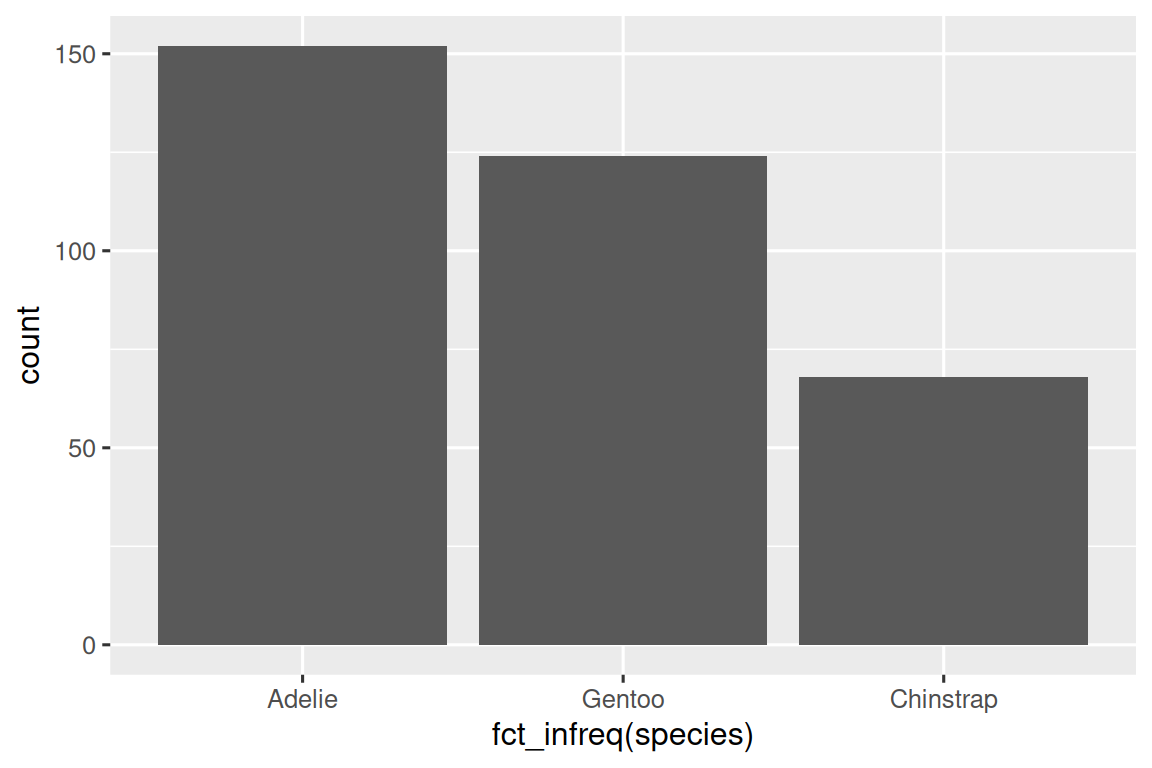
如果要对企鹅的体重等**数值变量(numerical variable)**进行可视化,可使用直方图geom_histogram():
ggplot(penguins, aes(x = body_mass_g)) +
geom_histogram(binwidth = 200)
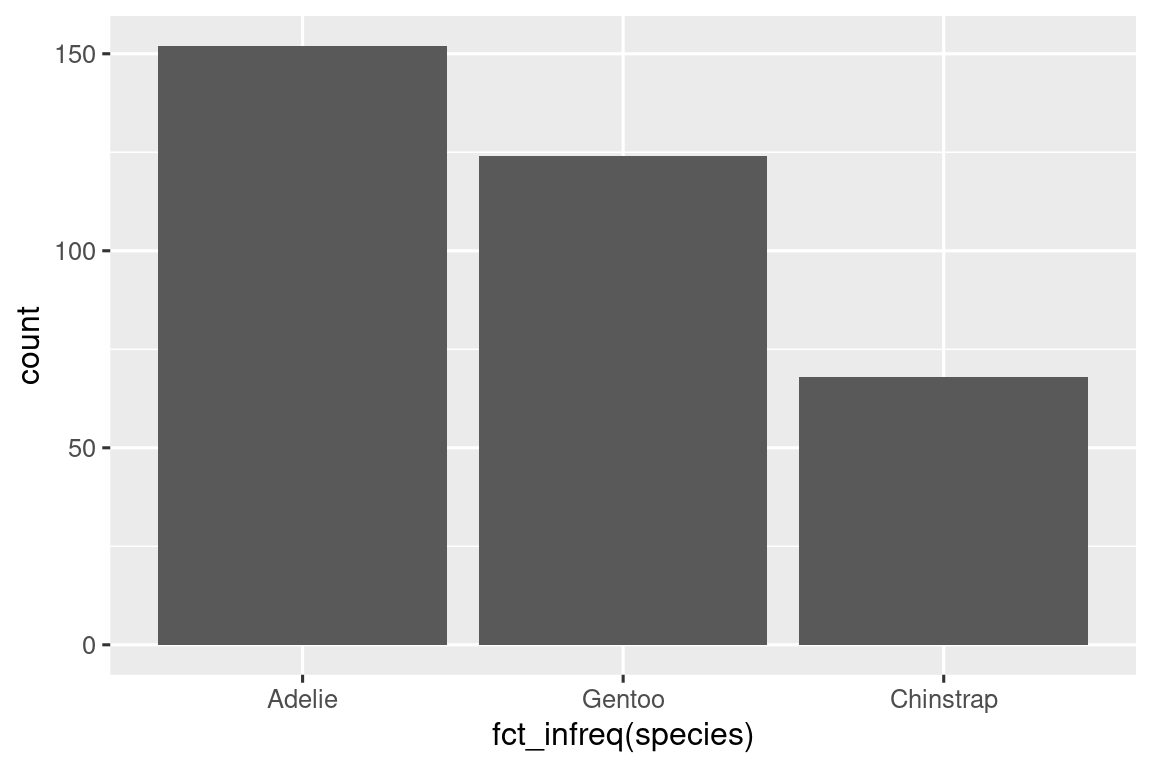
指令中的 binwidth 参数设置直方图中的间隔宽度。在应用直方图时,需要尝试多种 binwidth参数,以找到最顺眼且最合理的样式。比如设置为20时显然过于密集了:
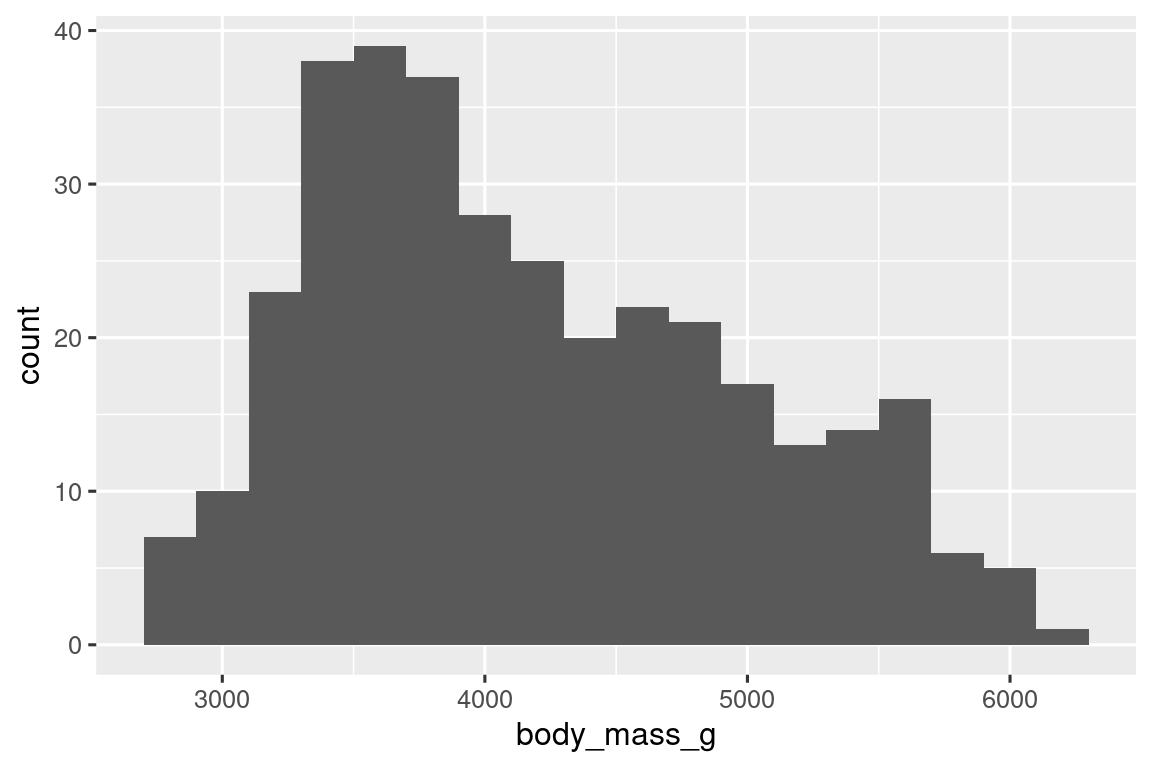
数值分布还可以用密度图geom_density()进行可视化,相当于连接直方图各个长条的顶点绘制的曲线:
ggplot(penguins, aes(x = body_mass_g)) +
geom_density()
#> Warning: Removed 2 rows containing non-finite outside the scale range
#> (`stat_density()`).
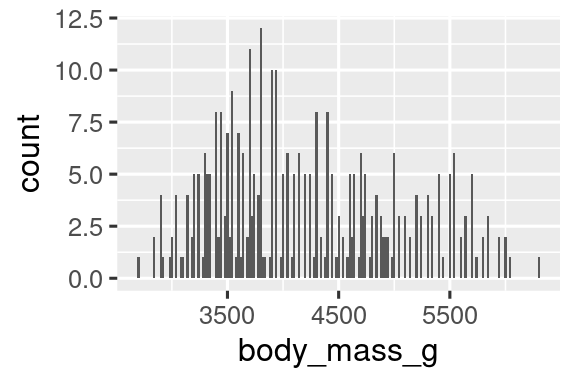
1.5 关系可视化
为了可视化变量间的关系,我们需要将至少两个变量映射到美学。下面将介绍用于可视化两个或多个变量之间关系的常用绘图。
1.5.1 数值变量和类别变量
要对数值变量和类别变量进行关系可视化,可使用箱线图geom_boxplot()。
箱线图由以下部分组成:
- 一个表示数据中间半部分范围的框,该距离称为四分位距 (IQR),从分布的第 25 个百分位数延伸到第 75 个百分位数。框中间有一条横线,显示分布的中位数,即第 50 个百分位数。这三条线体现数据的分散程度,以及分布是关于中位数对称还是偏向于某一侧。
- 超过框的任一边缘 IQR 1.5 倍的观测值的数据会以点的形式单独标注,称为outliers。
- 从框的两端延伸并到达最远的非异常值点的线称作须线(whisker)。
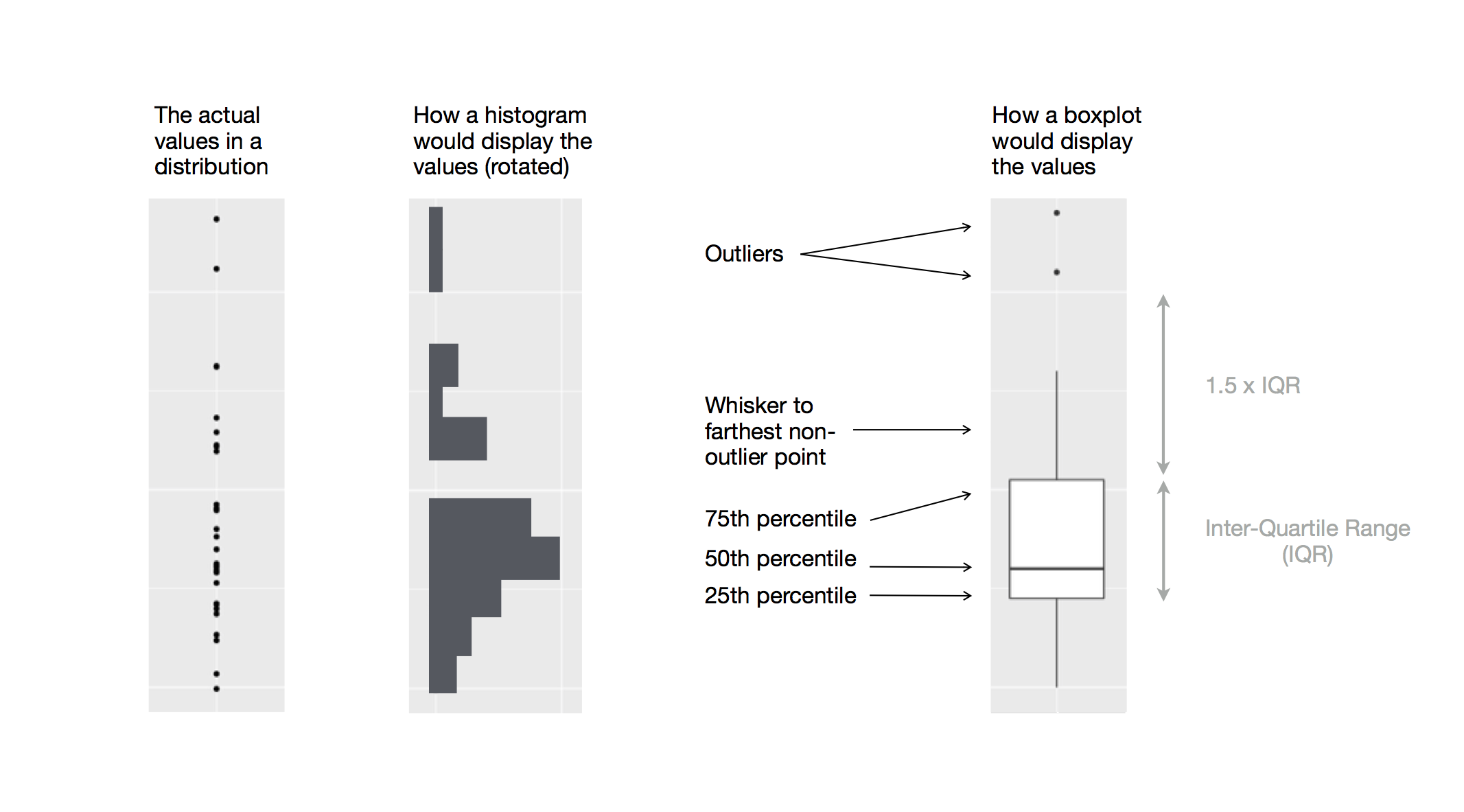
现在使用箱线图将企鹅体重与物种的关系可视化:
ggplot(penguins, aes(x = species, y = body_mass_g)) +
geom_boxplot()
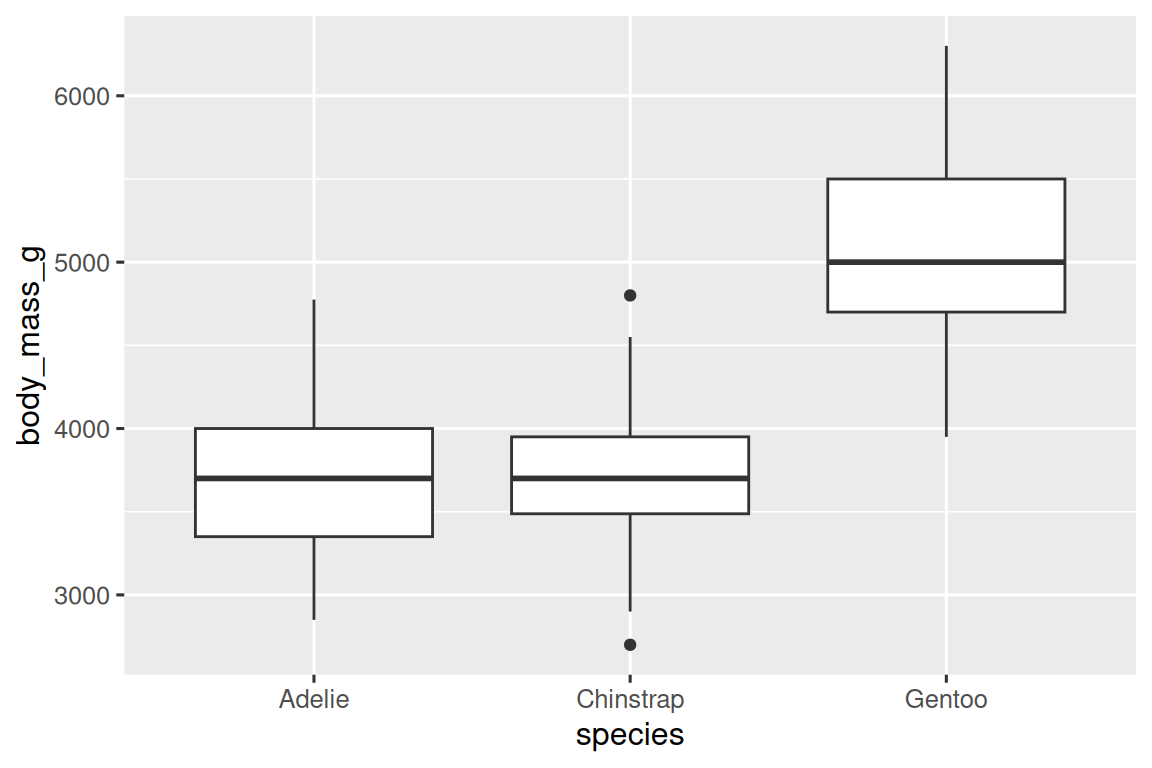
关系的可视化也可以使用密度图,不过较前文有所进阶。使用linewidth参数自定义线条粗细:
> ggplot(penguins, aes(x = body_mass_g, color = species)) +
+ geom_density(linewidth = 0.75)
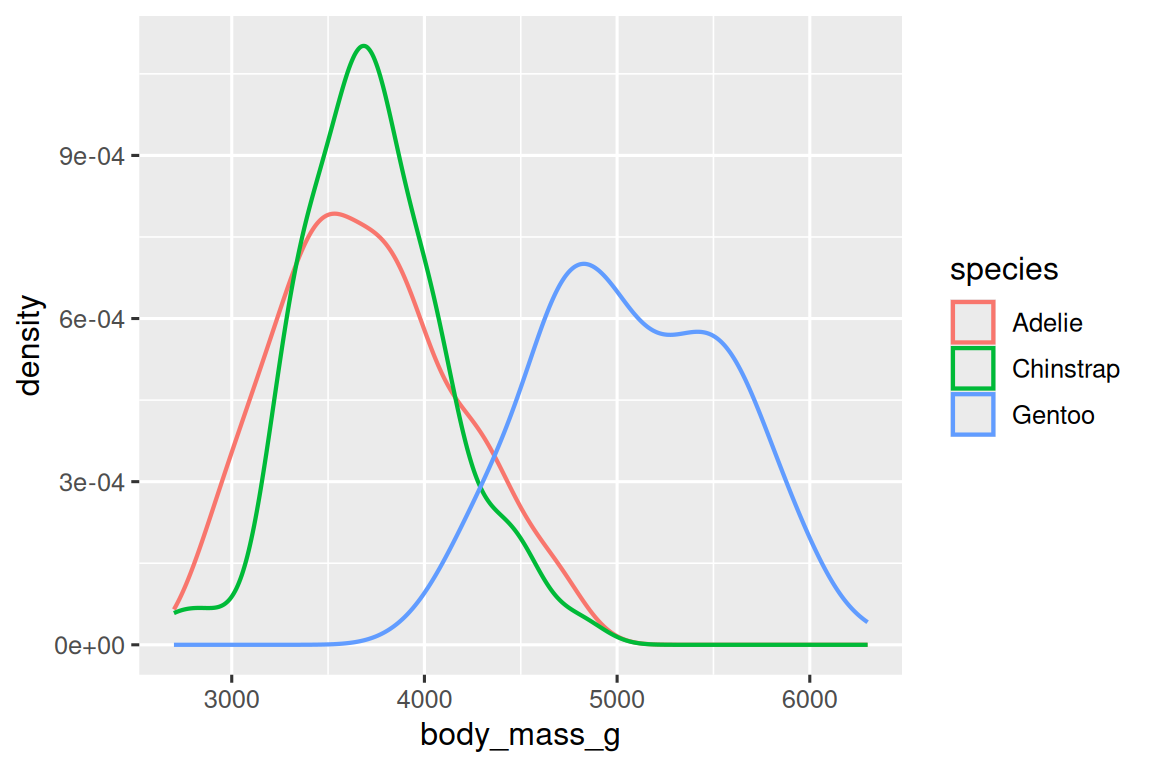
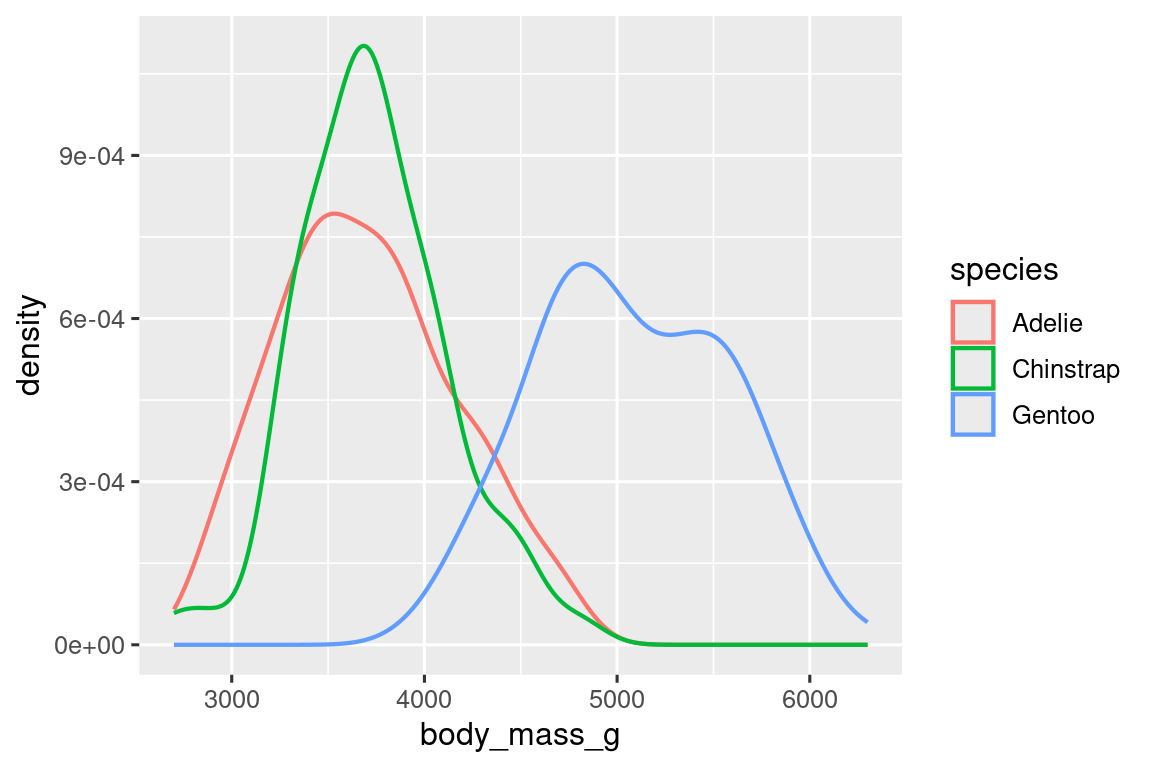
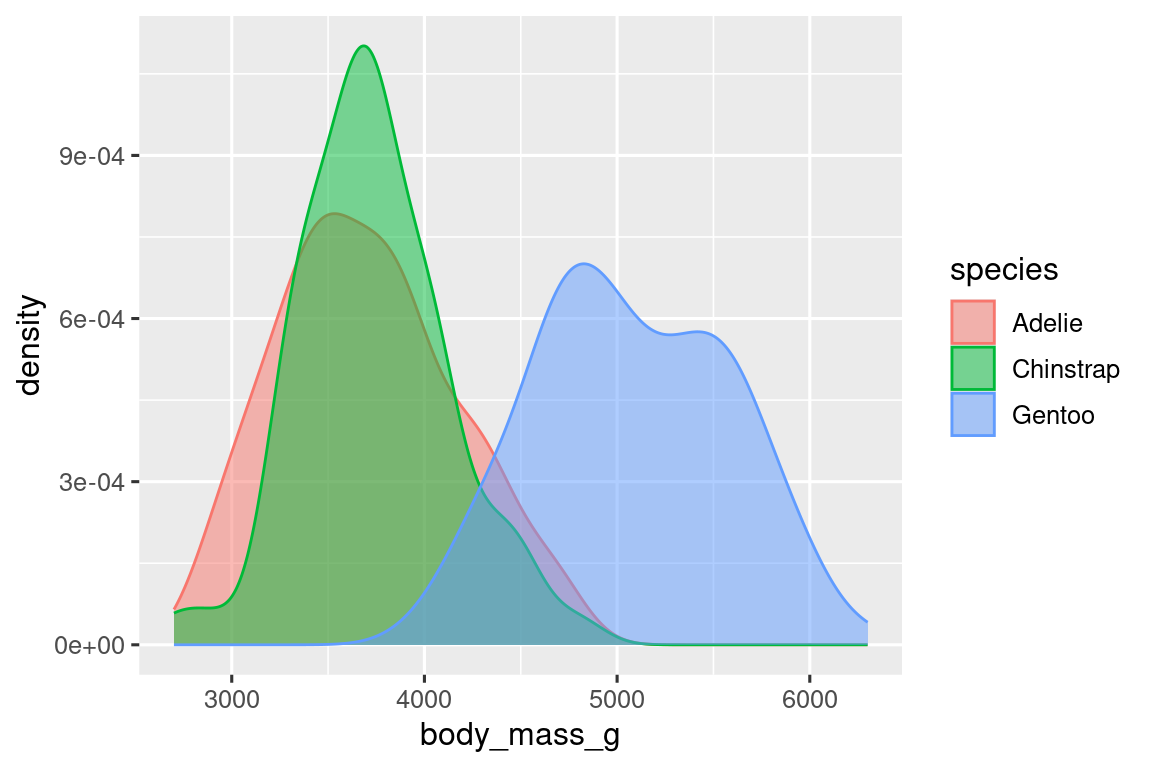
可以用fill参数为密度曲线填充颜色,同时使用alpha参数设置填充的透明度:
ggplot(penguins, aes(x = body_mass_g, color = species, fill = species)) +
geom_density(alpha = 0.5)
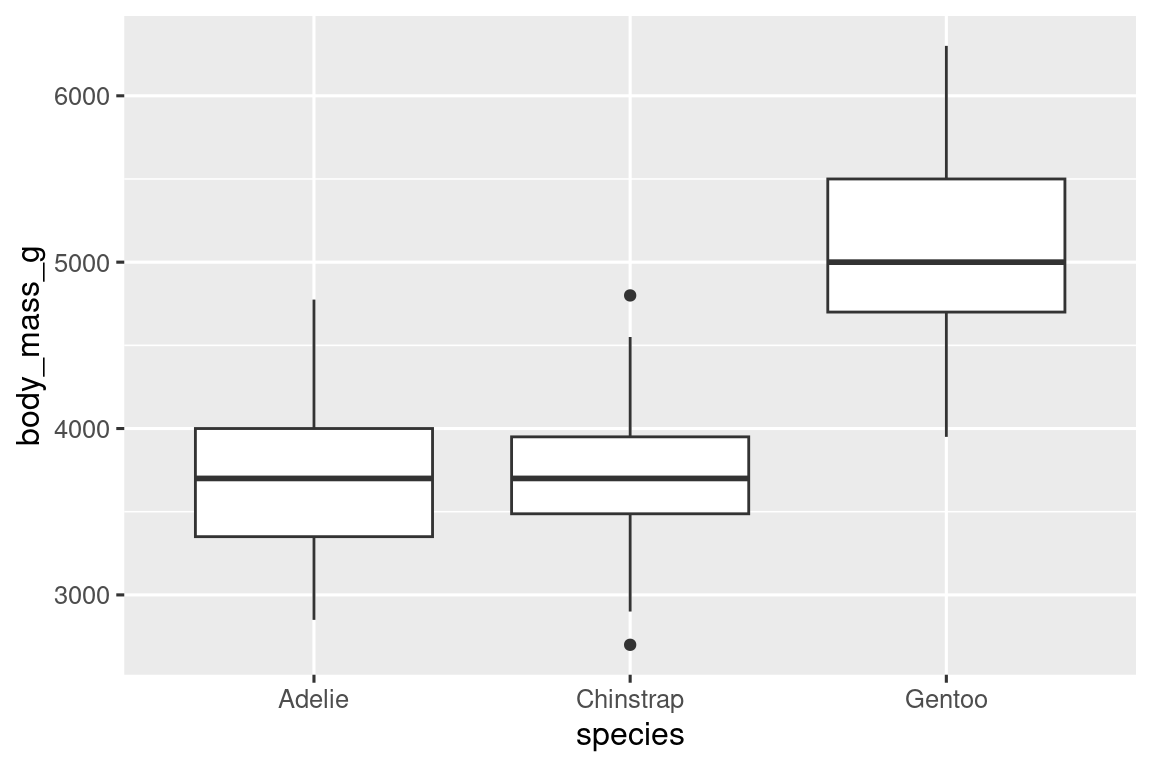
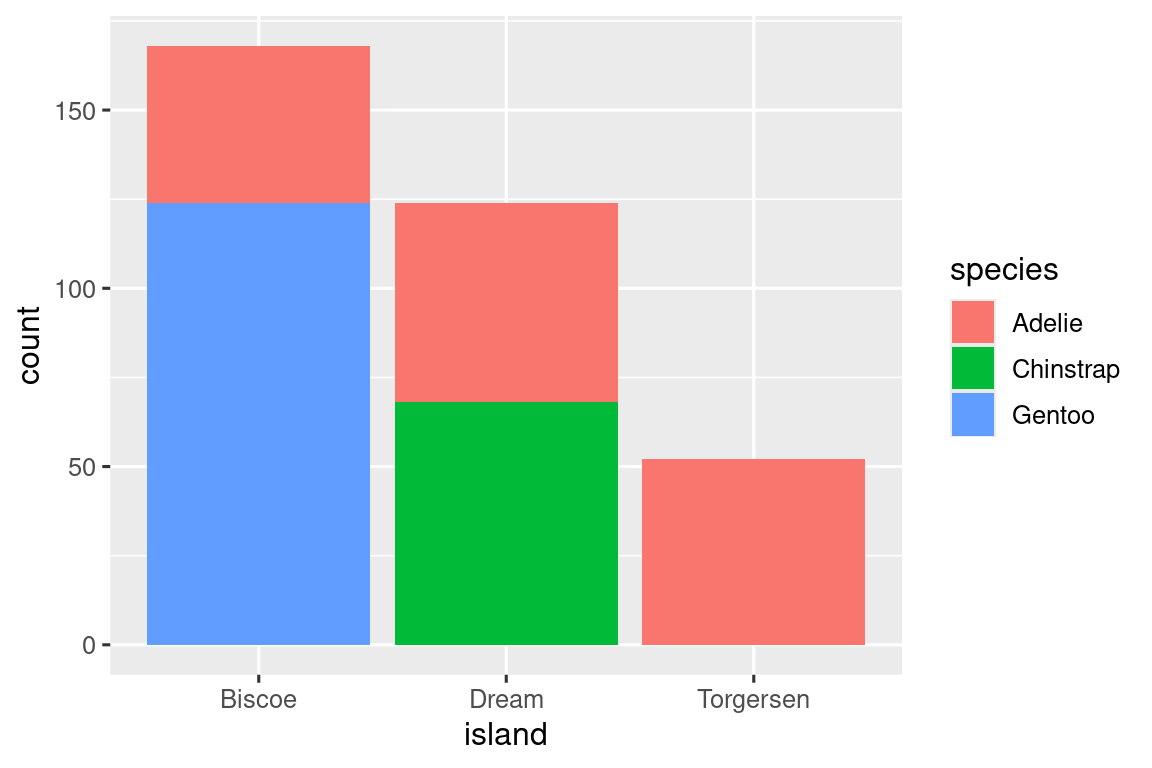
1.5.2 两个类别变量
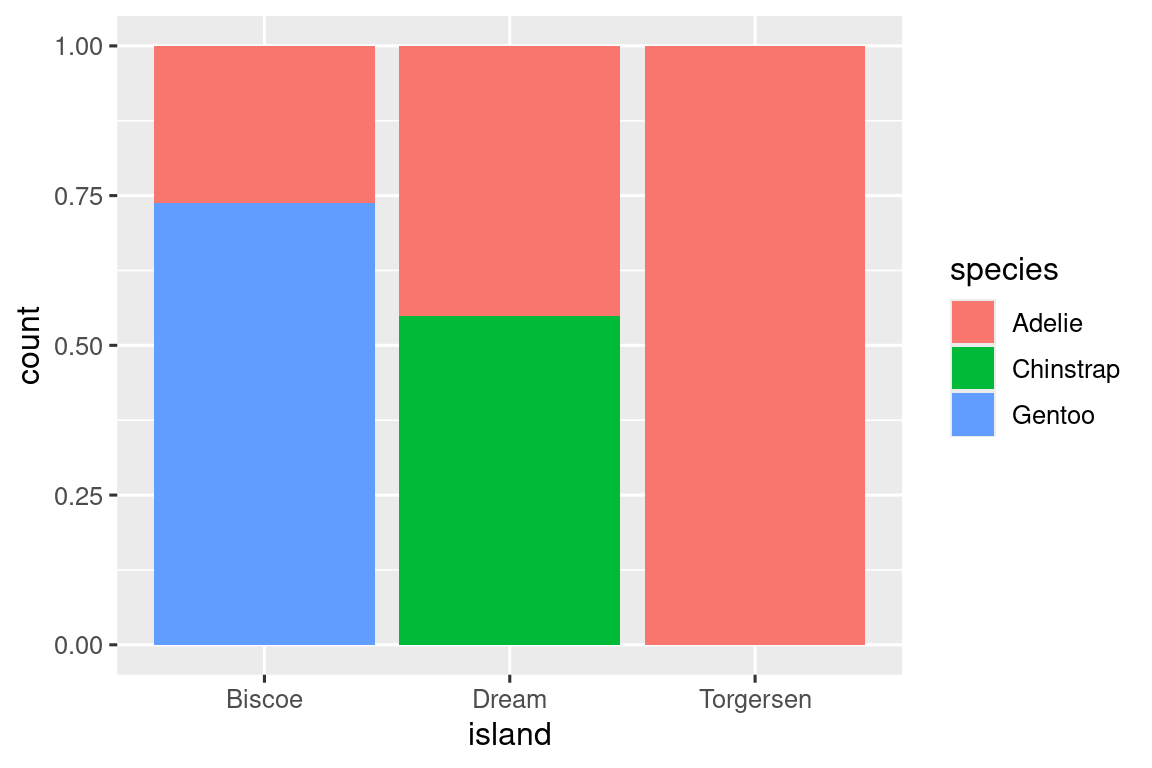
使用堆叠条形图来可视化两个类别变量的关系。例如要处理物种和岛名的关系:
ggplot(penguins, aes(x = island, fill = species)) +
geom_bar()
像这样直接生成的条形图反映了绝对数值,但是对于各岛企鹅物种占比的对比不太直观。此时可设置参数position="fill"的方式让相对频率更直观:
ggplot(penguins, aes(x = island, fill = species)) +
geom_bar(position = "fill")
1.5.3 两个数值变量
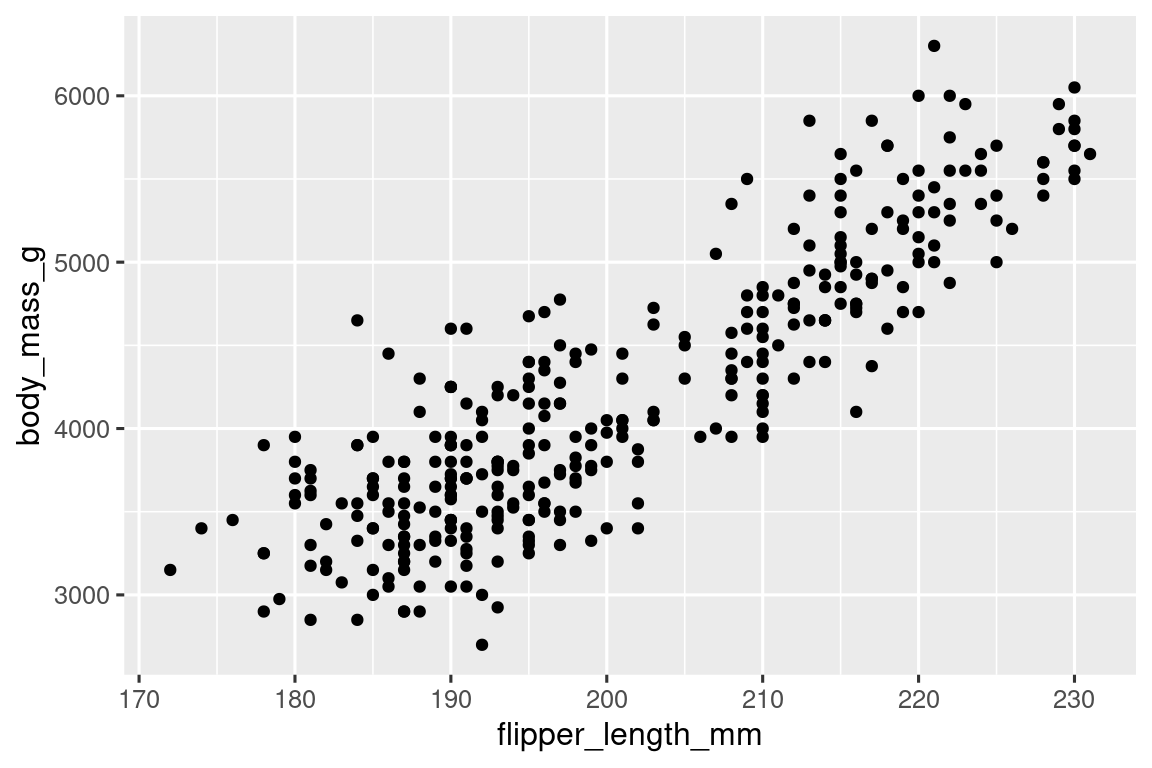
书中指出,散点图是可视化两个数值变量之间关系的最常用图。
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point()
1.5.4 三个或更多变量
针对三个变量,我们可以加入更多美学要素以表示变量,比如用点的颜色表示物种,用点的形状表示岛屿:
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = species, shape = island))
但是这样做的缺陷非常明显,图片十分杂乱,若变量更多则更糟糕。故而有另一种方案:分面。即使用多个子图以表示类别变量。
要进行分面,则使用facet_wrap()函数,参数为符号~后加上需要分面的类别变量名称。例如将岛屿进行分面:
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point(aes(color = species, shape = species)) +
facet_wrap(~island)
1.6 保存绘图
使用ggsave()函数保存最近一次所画图像,参数file可设置图像名称及路径。比如:
ggplot(penguins, aes(x = flipper_length_mm, y = body_mass_g)) +
geom_point()
ggsave(filename = "penguin-plot.png")


 https://qm.qq.com/q/QZibQd1hiq
https://qm.qq.com/q/QZibQd1hiq



 发表于 2025-11-10 21:48:39
发表于 2025-11-10 21:48:39
 照妖镜
照妖镜






